多臂赌博机有多个摇臂,赌徒在投入一个硬币后可选择按下其中一个摇臂,每个摇臂以一定的概率吐出硬币,但这个概率赌徒并不知道。赌徒的目标是通过一定的策略最大化自己的奖赏,即获得最多的硬币。
1,如果知道每个动作的价值,每次选择价值最高的动作。
2,否则将尝试机会平均分配给每个摇臂,最后将每个摇臂各自的平均吐币概率作为奖赏期望的近似估计。选择估值最高的动作称作开发(exploitation),选择其他动作称作试探(exploration)半岛体育app官方网站下载欢迎您。需要在开发和试探中取得平衡。
先随机试若干次,计算每个臂的平均收益,一直选均值最大那个臂。
增量描述:我们对某台赌博机投入第n枚硬币的奖励估计值用该赌博机前n-1次的奖励均值来近似,为了方便计算,我们可以将其描述为以下递推式,这样就只需要记录  和
和  即可得到
即可得到 

可以理解为 新的估计值 = 旧的估计值 + 学习率 * 误差
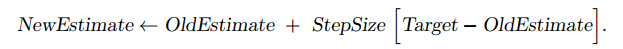
非平稳情况:前面假设赌博机问题的奖赏分布不会随时间的变化而变化,这种称作平稳赌博机问题。实际过程中,很多时候赌博机的收益概率分布是随时间变化的,是一个非平稳过程。在这种情况下,最近的奖赏相比于前面的奖赏通更重要,给近期的奖赏赋予比过去很久的奖赏更高的权值是一种合理的处理方式,例如使用固定步长
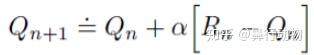
这样越早的奖励对当前影响越小
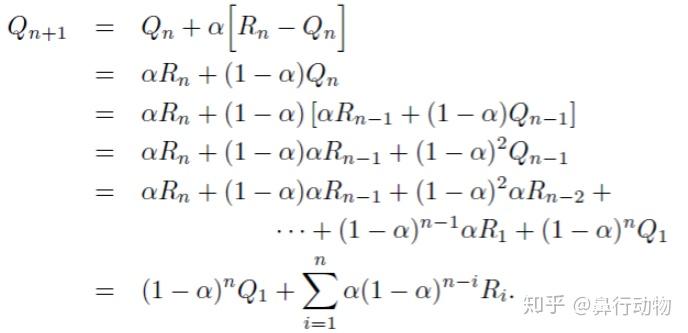
原理:对开发和试探进行折中,每次以  概率进行试探,
概率进行试探,  的概率进行开发。
的概率进行开发。
优点:简单有效
局限:1,收敛较慢。2,选择最优动作的概率将收敛到大于
改进:随着步数的增加逐渐减少
原理:乐观初始值方法通过给每个赌博机设置较高的初始奖励预期,来增加早期的试探过程,尽可能让每个赌博机都被尝试几次,从而避免收敛到局部最优。
举个例子,假设每台赌博机产生的奖励服从均值为0,方差为1的高斯分布,而赌徒对每一台赌博机给出的预期奖励都是5。然后赌徒开始投币,发现第一台赌博机吐出的奖励让他大失所望(几乎不可能给出大于5的奖励值),于是赌徒开始去探索其他的机器。最终,所有动作在估计值收敛之前都被尝试了好几次。
优点:有效避免局部最优
局限:乐观初始值在平稳问题中非常有效,而不太适合非平稳问题。
-贪心实际上是一种盲目的选择,因为它不太会选择接近贪心或者不确定性特别大的动作。
原理:根据动作的潜力来选择可能事实上是最优的动作,即考虑到它们的估计值有多接近最大值,以及这些估计的不确定性。UCB方法的核心思想就是考虑了每个动作被选择了多少次,并通过公式让policy更倾向于选择较少被选择的动作。
算法流程:
1,初始化,将每个赌博机都尝试一遍。
2,按照如下公式计算每个赌博机的得分,选择得分最高的机器
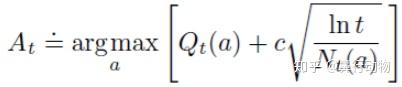
其中  表示在时刻
表示在时刻 之前动作
之前动作 被选择的次数(若为0则a被认为是满足最大化条件的动作)。
被选择的次数(若为0则a被认为是满足最大化条件的动作)。 是一个大于0的数,控制试探的程度。
是一个大于0的数,控制试探的程度。  是目前收益的均值。
是目前收益的均值。
平方根项是对动作值估计的不确定性或方差的度量。随着 的增加,这一项减小,即不确定性减小;每次选择以外的动作时,增大,而 没有变化,所以不确定性增加。
3,根据选择的结果更新t和

优点:一般情况下效果比 -贪心好
局限:
1,难以处理非平稳问题。
2,在处理大型状态空间时,特别是当处理利用函数逼近器来作为值函数的问题时。
前面几种方法都是根据行动的奖励估值选择行动,然而这并不是唯一的方法。
原理:梯度赌博算法对t时刻动作考虑一个数值化的偏好函数 ,偏好函数越大,动作被选择的概率越高。我们关注的偏好是一个动作对另一个动作的相对偏好,因此每一个动作的偏好函数增加相同值对于softmax分布确定的动作概率没有任何影响。
,偏好函数越大,动作被选择的概率越高。我们关注的偏好是一个动作对另一个动作的相对偏好,因此每一个动作的偏好函数增加相同值对于softmax分布确定的动作概率没有任何影响。
算法流程:
1,初始化奖励和偏好
2,根据softmax选择偏好函数值最大的行动计算奖励
3,更新偏好函数
在t时刻,选择行为a的概率为:
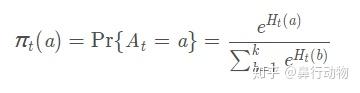
算法对每个行为偏好的更新公式为:
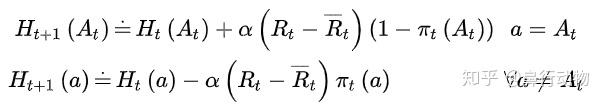
 是t时刻之前获得的奖励的均值,这个作为一个参考值,如果当前获得的奖励大于均值,就增加偏好值,如果小于均值,就减小偏好值。其他没有选择的行为的偏好值就向相反方向移动。
是t时刻之前获得的奖励的均值,这个作为一个参考值,如果当前获得的奖励大于均值,就增加偏好值,如果小于均值,就减小偏好值。其他没有选择的行为的偏好值就向相反方向移动。
我们知道,随机梯度上升确实能确保收敛到最优值,那么问题就在于,这个形式是否就是“随机梯度上升”的形式呢?只需证明下式:
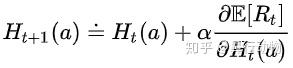
具体证明过程参考这里
原理:
1,假设每个臂能产生收益的概率是p,并且p的概率分布符合beta(wins, lose);
2,每个臂都维护其beta分布的参数,每次试验后,选中一个臂摇一下,有收益的话wins+1,否则,lose+1;
3,选择臂的方式则是:通过用每个臂现有的beta分布产生一个随机数,选择所有臂中随机数最大的臂去摇。
np.argmax(pymc.rbeta(1 + successes , 1 + totals - successes))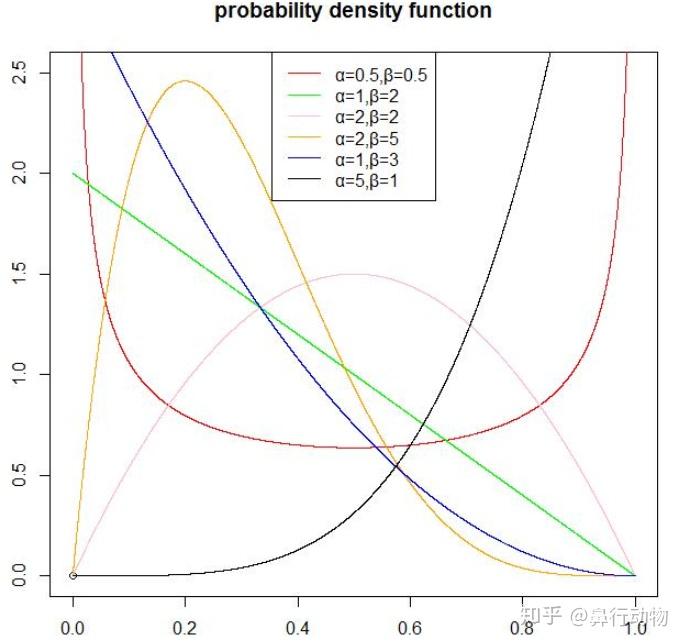
为什么选择贝塔分布?
- 贝塔分布是共轭先验分布半岛体育app官方网站下载,先验和后验有相同形式
- a=b时对称半岛体育app官方网站下载,a>b时右偏,a<b时左偏
- b越大越陡峭
- 总体思想和UCB类似
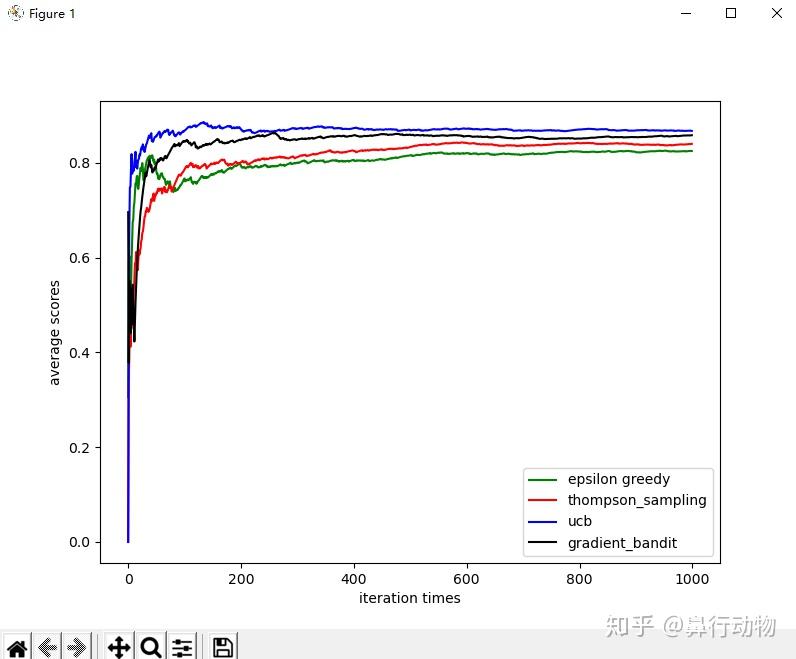
每种算法性能的特征倒U形状,所有算法在其参数的中间值上表现最佳。
在评估一种方法时,我们不仅要关注它在最佳参数设置下的表现,还要关注它对参数值的敏感程度。可以看到。所有这些算法都相当不敏感,在一系列变化大约一个数量级的参数值上表现良好。总的来说,在这个问题上,UCB似乎表现最佳。
bandit算法在推荐系统中有着广泛的应用。推荐系统里面有两个经典问题:EE(开发与试探)和冷启动。Bandit算法是一种简单的在线学习算法,常常用于尝试解决这两个问题。
其中,Exploitation就是:对用户比较确定的兴趣,当然要利用开采迎合,好比说已经挣到的钱,当然要花;而Exploration就是:光对着用户已知的兴趣使用,用户很快会腻,所以要不断探索用户新的兴趣才行, 四虎影院最新网址更新这就好比虽然有一点钱可以花了,但是还得继续搬砖挣钱,不然花完了就得喝西北风。首存送彩金38
用户冷启动问题,也就是面对新用户时,如何能够通过若干次实验,猜出用户的大致兴四虎github趣
风黑料不打详清云:强化学习读书笔记之Multi-armed四虎影院在线观看 Bandits及实现(一)四虎影院最新网址更新